Chapter 3 Linear Regresssion
library(tidyverse)We have a sample of 100, 5 different variables (p), and an X matrix. We are making uniform variables, and we will jam them into a matrix such that the number of rows is equal to n.
n <- 100
p <- 5
X <- matrix(runif(p * n),
nrow=n)Then we can create some Y’s based on betas and noise. To do so, we need betas. We will make all of them zeros, except for one of them! We also need to define our noise.
beta <- rep(0, p)
beta[sample(p, 1)] <- 1
noise <- rnorm(n)
# %*% Matrix multiplication in R
#X is a matrix of 100 by 5
#Beta is a matrix of 5
Y <- X %*% beta + noiseThe above is generating data according to a linear model! So what does this do? We have X and a bunch of 0 betas, except for one special one. The Y then will depend only on the one column!
If we don’t know which beta matters, we just fit y against x and print out a summary.
ols <- lm(Y ~ X)
summary(ols)##
## Call:
## lm(formula = Y ~ X)
##
## Residuals:
## Min 1Q Median 3Q Max
## -3.03705 -0.52657 0.00186 0.63090 2.93349
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 0.4710 0.4387 1.074 0.286
## X1 -0.1822 0.3480 -0.523 0.602
## X2 -0.1492 0.3595 -0.415 0.679
## X3 0.1422 0.3652 0.389 0.698
## X4 0.5893 0.3639 1.619 0.109
## X5 -0.3065 0.4047 -0.757 0.451
##
## Residual standard error: 1.017 on 94 degrees of freedom
## Multiple R-squared: 0.03589, Adjusted R-squared: -0.01539
## F-statistic: 0.6999 on 5 and 94 DF, p-value: 0.6249So only one of them is statistically significant! This shows it should be the 5th! We can see the truth:
beta## [1] 0 0 0 1 0This is a good example of fitting basic regression.
Lets look at the y and subtract the the coefficients to find the residuals: note: length(ols$coefficients) is 6, but dimensions of X is going to be 5.So we will need to cbind. So this is y minus the fitted data from the regression. When we do summary of ols, we get a bunch of estimates. The intercept and the estimated coefficients. These are estimates from the regression based on the data. Using these, we can recover and estimate and then find the difference to see what the residuals are!
resid <- Y - cbind(1, X) %*% ols$coefficients
#this is the manual version of:
resid <- ols$residualsNow let’s do the residuals against the true beta! We are subtracting the x values against the true beta. True beta means this is the beta that created the data. This is how god created the world. It is the actual physical value. The above residuals are from the regression of the fitted data.
resid_from_truth <- Y - X %*% betaWe can plot this as well!
plot(density(resid_from_truth))
lines(density(resid), col = "red")
abline(v = 0)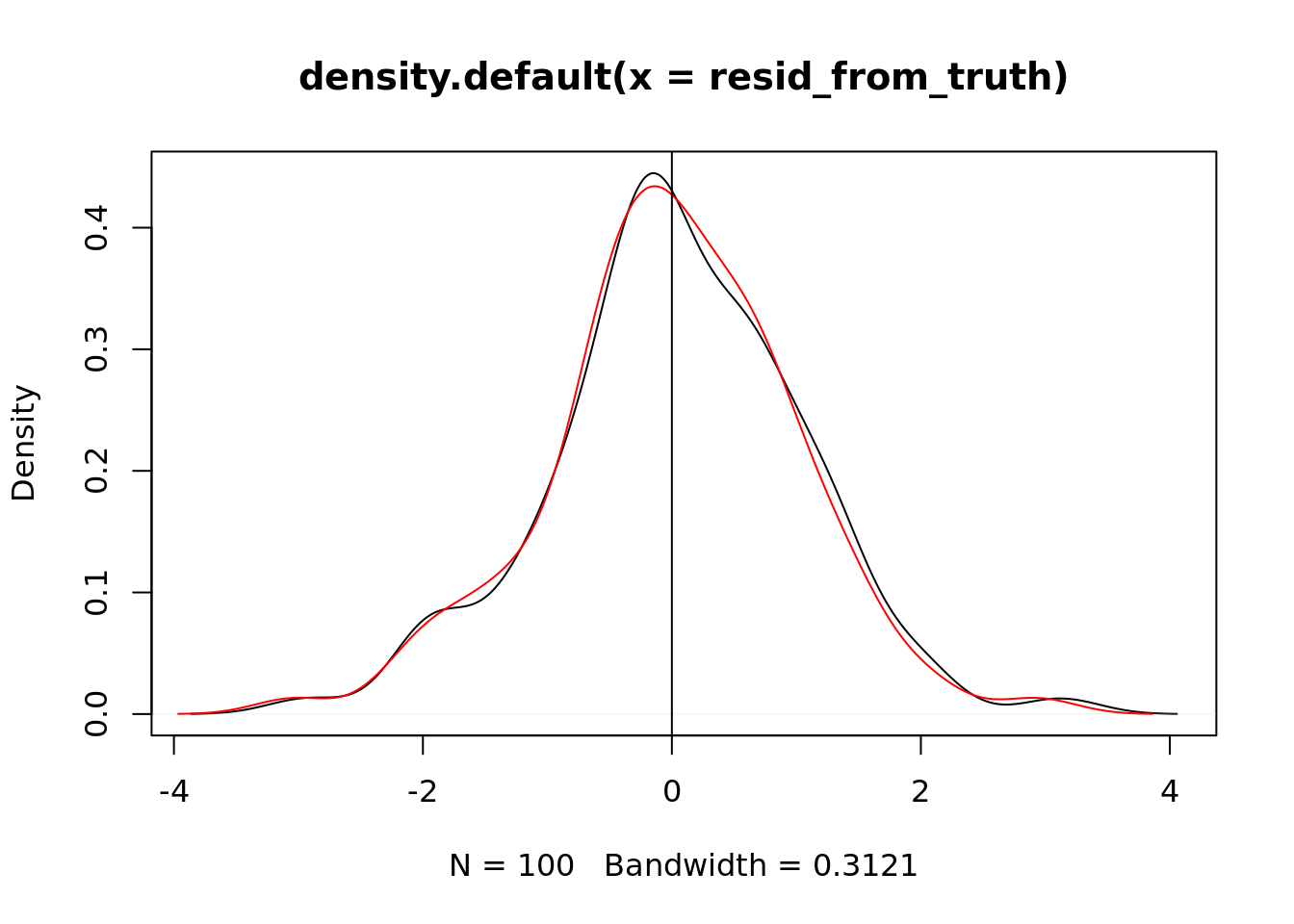
This might not be enough contrast for us to tell. How can we quantify the difference? Let’s see the difference between the two:
mean(abs(resid))## [1] 0.7565599mean(abs(resid_from_truth))## [1] 0.7698125We want the smaller value! The simulated data based values will always have a smaller residual mean than the real values! This is rather disturbing. The fitted coefficients from your regression will always be better than the “true” coefficients. Why is this bad?
Normally we want to use regression to find the natural coefficients or natural facts about the world. These are based on some “truth”. If you can collect noisy data but our algo prefers the fitted data rather than the truth we have a problem. We want our error minimized at the “truth”. Our regression here doesn’t like the true answer and it prefers something else. It actually prefers the training data.
This is because we use the same data to train and evaluate. Our data is just optimized for this one thing. If we know how you are going to evaluate me, I will just optimize for that specific thing.
So let’s generate another set of data: new Y using the same beta and x but with new noise values: Testing data generated from the same population but not used for training the model
new_noise <- rnorm(n)
new_Y <- X %*% beta + new_noise
new_resid <- new_Y - cbind(1, X) %*% ols$coefficients
new_resid_from_truth <- new_Y - X %*% beta
mean(abs(new_resid))## [1] 0.9326886mean(abs(new_resid_from_truth))## [1] 0.9269536Our takeaway is don’t always cross over your data because you risk overfitting.
3.1 Non linear data
Let’s create new data that is nonlinear. This is mini sine data.
n <- 100
X <- runif(100, max = 2 * pi / 4 * 3)
Y <- 0.1+-3 * sin(X) + rnorm(n, sd = 0.5)Then we can recreate our linear regression and the plot.
ols <- lm(Y ~ X)
summary(ols)##
## Call:
## lm(formula = Y ~ X)
##
## Residuals:
## Min 1Q Median 3Q Max
## -2.3998 -0.9334 -0.2654 0.9223 3.5911
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -3.6001 0.2826 -12.74 <2e-16 ***
## X 1.2394 0.1032 12.01 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 1.316 on 98 degrees of freedom
## Multiple R-squared: 0.5955, Adjusted R-squared: 0.5914
## F-statistic: 144.3 on 1 and 98 DF, p-value: < 2.2e-16plot(X, Y)
abline(lm(Y ~ X))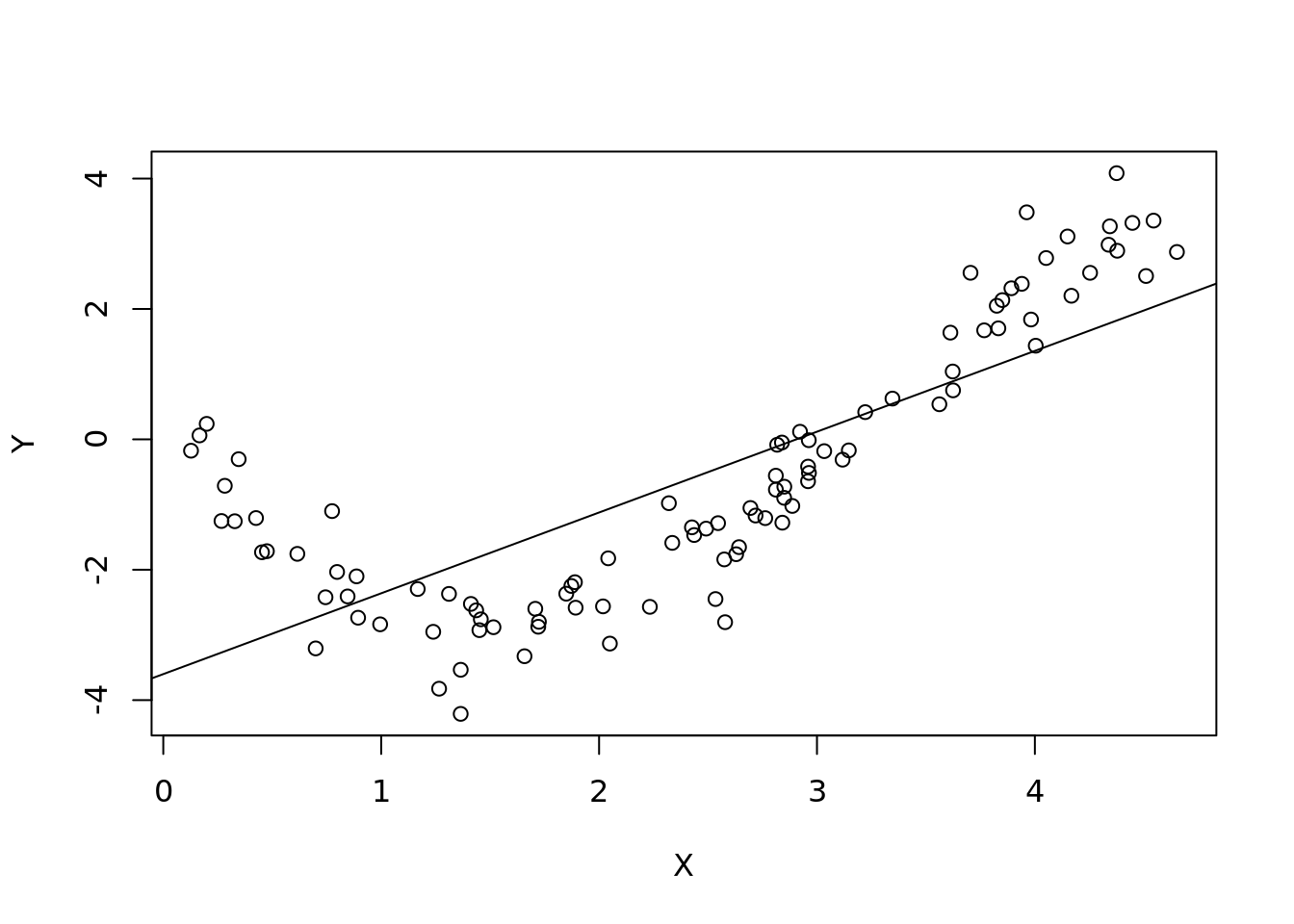
As expected our linear model created a line that doesn’t look to fit too well. Let’s look at the residual plot instead. We
par(mfrow=c(1,2))
plot(ols$residuals)
abline(h=0)
plot(X, ols$residuals)
abline(h = 0)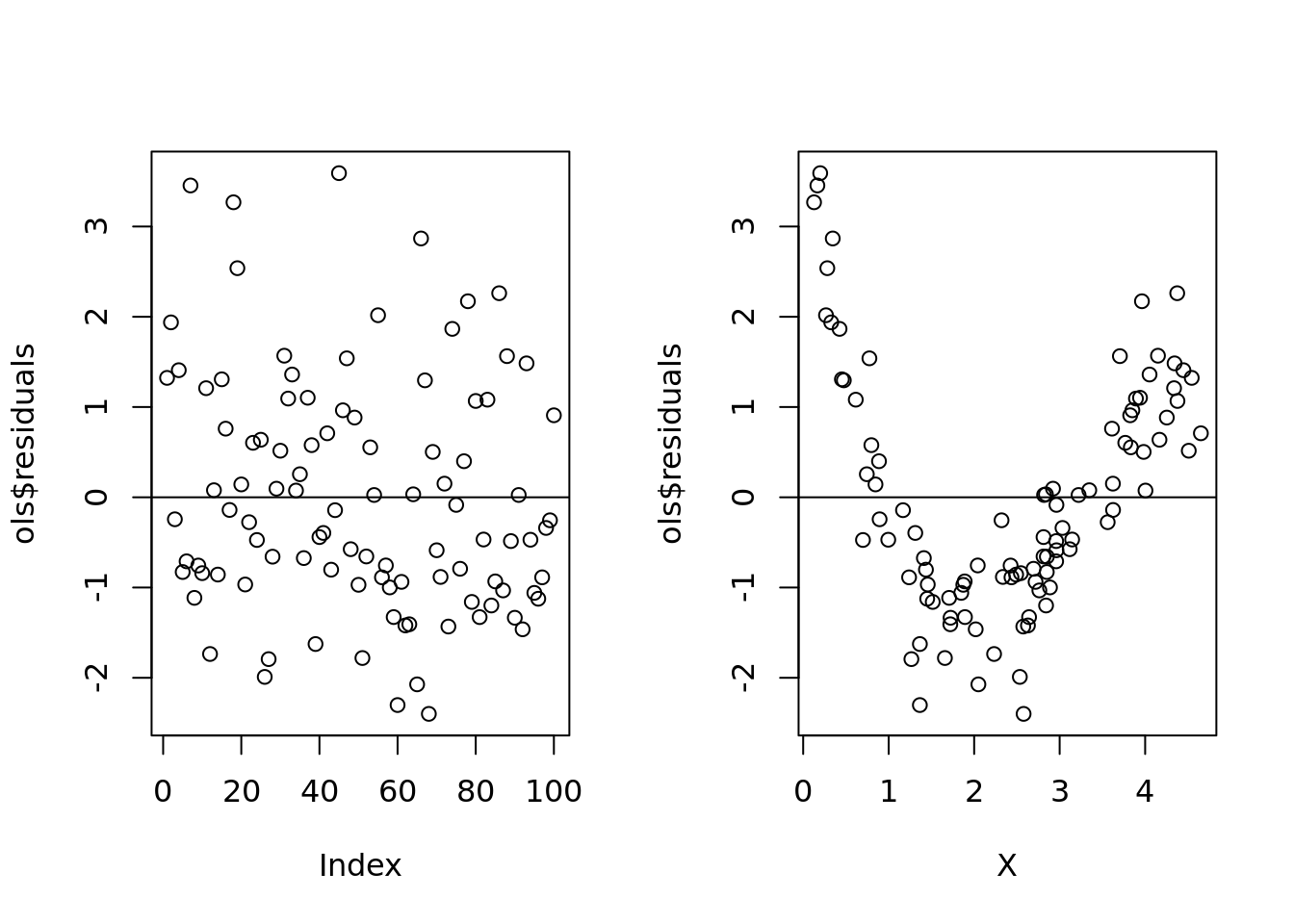
Xs were generated in a random order so we we just use the index, it looks random and normal. But when we sort by x value, we see that there is definitely a problem and we need to add a quadratic term.
We can then find the mean squared error:
n <- 100
Y <- 0.1+-3 * sin(X) + rnorm(n, sd = 0.5)
#Y - y hat squared
mean((Y - ols$fitted.values) ^ 2)## [1] 1.773755Plot the MSE vs the number of polynomials used on the x axis. Do this for both the training vs the testing data.
We can regress on matrices in R which makes this really easy. So let us create an X_matrix, where for each degree, we raise x to that number of degrees. This matrix will be n rows and degrees columns.
n <- 100
degrees <- 1:50
X <- runif(n, max = 2 * pi / 4 * 3)
Y <- 0.1+-3 * sin(X) + rnorm(n, sd = 0.5)
new_Y <- 0.1+-3 * sin(X) + rnorm(n, sd = 0.5)
X_mat <- sapply(degrees, function(i)
X ^ i)For example
plot(X, X_mat[,5])
We can do this through a loop.
#create an empty vector
MSEs <- rep(NA, length(degrees))
#Create empty vector for tests
test_MSEs <- MSEs
for (i in seq_along(degrees)) {
# regress for each power on each loop
ols <- lm(Y ~ X_mat[, 1:i])
# record the MSEs
MSEs[i] <- mean(ols$residuals ^ 2)
# do again for new set, only word because we use the same X
new_errors <- new_Y - ols$fitted.values
# record
test_MSEs[i] <- mean(new_errors ^ 2)
}Plot in base R
plot(degrees, MSEs, type = "b",
ylim = c(0, max(test_MSEs)))
lines(degrees, test_MSEs, type = "b", col = "red")
legend("topright",
legend = c("Test", "Train"),
fill = c("red", "black"))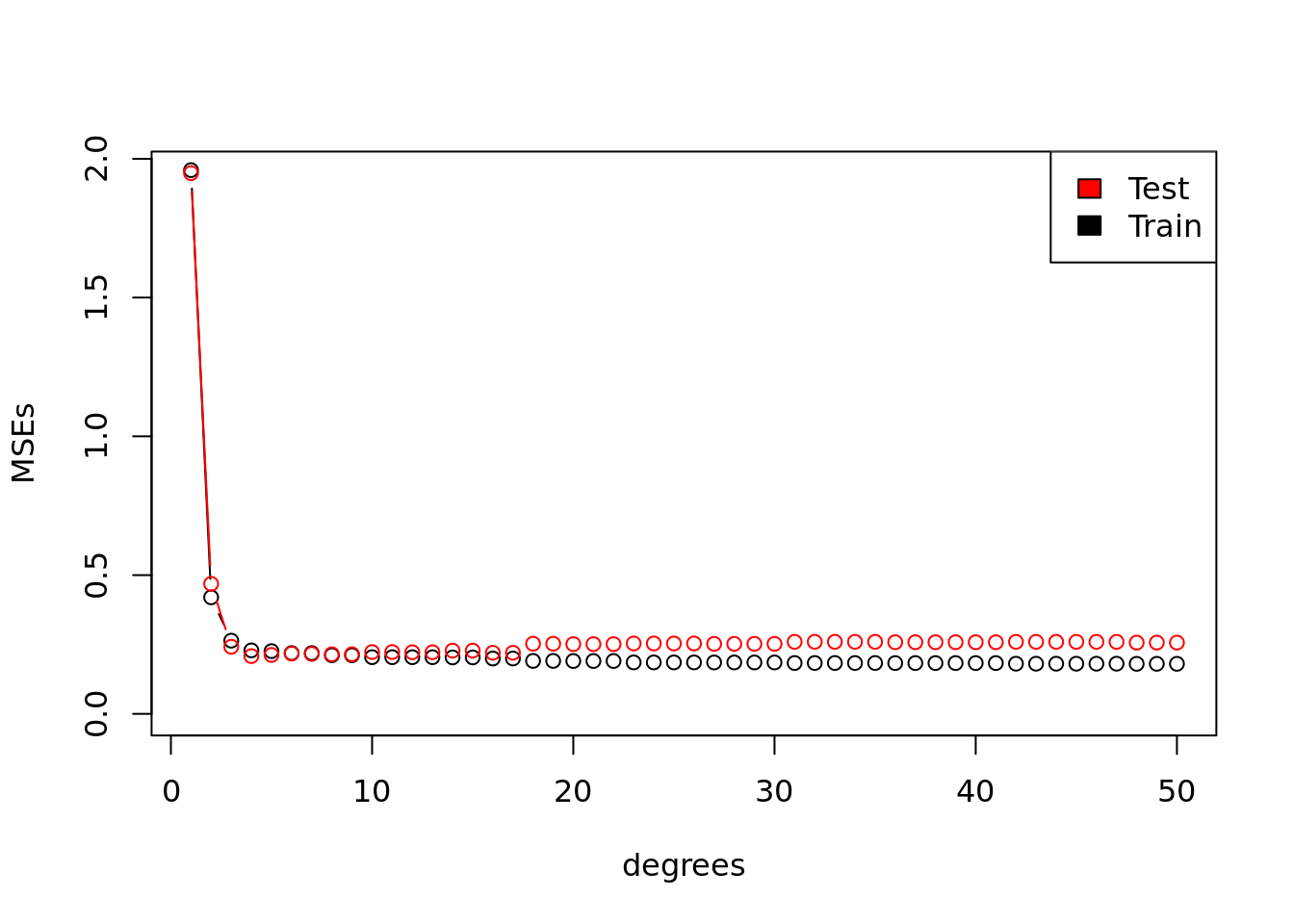
Plot in tidyverse
summary(ols)##
## Call:
## lm(formula = Y ~ X_mat[, 1:i])
##
## Residuals:
## Min 1Q Median 3Q Max
## -1.20644 -0.24450 -0.01122 0.29082 0.89411
##
## Coefficients: (28 not defined because of singularities)
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 1.876e+00 3.780e+00 0.496 0.621
## X_mat[, 1:i]1 -4.892e+01 1.342e+02 -0.365 0.716
## X_mat[, 1:i]2 4.172e+02 1.778e+03 0.235 0.815
## X_mat[, 1:i]3 -2.566e+03 1.215e+04 -0.211 0.833
## X_mat[, 1:i]4 1.156e+04 4.929e+04 0.234 0.815
## X_mat[, 1:i]5 -3.598e+04 1.289e+05 -0.279 0.781
## X_mat[, 1:i]6 7.602e+04 2.289e+05 0.332 0.741
## X_mat[, 1:i]7 -1.102e+05 2.851e+05 -0.387 0.700
## X_mat[, 1:i]8 1.110e+05 2.532e+05 0.438 0.662
## X_mat[, 1:i]9 -7.800e+04 1.605e+05 -0.486 0.628
## X_mat[, 1:i]10 3.753e+04 7.104e+04 0.528 0.599
## X_mat[, 1:i]11 -1.166e+04 2.064e+04 -0.565 0.574
## X_mat[, 1:i]12 1.923e+03 3.226e+03 0.596 0.553
## X_mat[, 1:i]13 NA NA NA NA
## X_mat[, 1:i]14 -4.969e+01 7.725e+01 -0.643 0.522
## X_mat[, 1:i]15 NA NA NA NA
## X_mat[, 1:i]16 2.047e+00 3.043e+00 0.673 0.503
## X_mat[, 1:i]17 NA NA NA NA
## X_mat[, 1:i]18 -7.467e-02 1.085e-01 -0.688 0.493
## X_mat[, 1:i]19 NA NA NA NA
## X_mat[, 1:i]20 1.794e-03 2.588e-03 0.693 0.490
## X_mat[, 1:i]21 NA NA NA NA
## X_mat[, 1:i]22 NA NA NA NA
## X_mat[, 1:i]23 -5.136e-06 7.493e-06 -0.686 0.495
## X_mat[, 1:i]24 NA NA NA NA
## X_mat[, 1:i]25 NA NA NA NA
## X_mat[, 1:i]26 NA NA NA NA
## X_mat[, 1:i]27 3.057e-09 4.653e-09 0.657 0.513
## X_mat[, 1:i]28 NA NA NA NA
## X_mat[, 1:i]29 NA NA NA NA
## X_mat[, 1:i]30 NA NA NA NA
## X_mat[, 1:i]31 -1.979e-12 3.212e-12 -0.616 0.540
## X_mat[, 1:i]32 NA NA NA NA
## X_mat[, 1:i]33 NA NA NA NA
## X_mat[, 1:i]34 NA NA NA NA
## X_mat[, 1:i]35 NA NA NA NA
## X_mat[, 1:i]36 1.772e-16 3.184e-16 0.557 0.579
## X_mat[, 1:i]37 NA NA NA NA
## X_mat[, 1:i]38 NA NA NA NA
## X_mat[, 1:i]39 NA NA NA NA
## X_mat[, 1:i]40 NA NA NA NA
## X_mat[, 1:i]41 NA NA NA NA
## X_mat[, 1:i]42 -2.417e-21 5.021e-21 -0.481 0.632
## X_mat[, 1:i]43 NA NA NA NA
## X_mat[, 1:i]44 NA NA NA NA
## X_mat[, 1:i]45 NA NA NA NA
## X_mat[, 1:i]46 NA NA NA NA
## X_mat[, 1:i]47 NA NA NA NA
## X_mat[, 1:i]48 2.177e-26 5.338e-26 0.408 0.685
## X_mat[, 1:i]49 NA NA NA NA
## X_mat[, 1:i]50 NA NA NA NA
##
## Residual standard error: 0.484 on 77 degrees of freedom
## Multiple R-squared: 0.9571, Adjusted R-squared: 0.9448
## F-statistic: 78.05 on 22 and 77 DF, p-value: < 2.2e-16This should be really concerning. It would mean strong colinearity. R is doing us a favor and automatically dropping some redundant features.
Create data under the so called regression model. Regression is an algo, but it is also a model for creating data. ODS is a least square algoristhm.
n <- 100
p <- 5
# God knows this!
params <- runif(p, -10, 10)
features <- matrix(rnorm(n * p),
nrow=n, ncol=p)
X <- features
X1 <- matrix(rnorm(n * p),
nrow=n, ncol=p)
noise <- rnorm(n)
noise1 <- rnorm(n)
Y1 <- X %*% params + noise
Y2 <- 0
for(i in seq_len(p)){
Y2 <- Y2 + params[i] * X1[, i]
}
Y2 <- Y2 + noise1
plot(X[,1], Y1)
points(X1[, 1], Y2, col="red")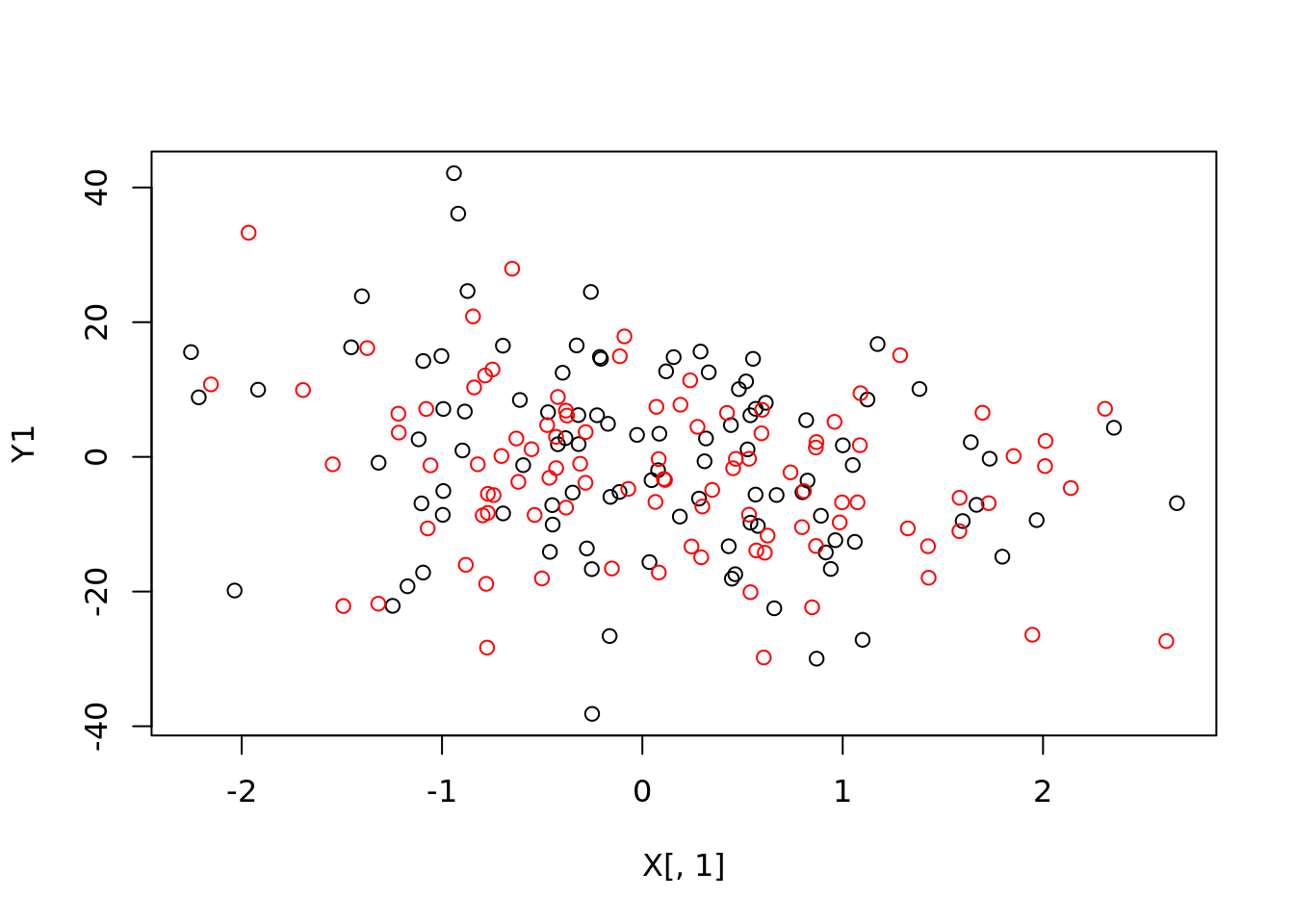
df <- as.data.frame(cbind(Y,X))
dim(df)## [1] 100 6head(df,2)## Y V2 V3 V4 V5 V6
## 1 -2.844331 0.04596886 -0.0122414 -0.3030977 -0.5512452 -0.3911246
## 2 -1.925567 0.11862475 -0.3060970 0.1959116 1.7319732 0.2819692names(df) <- c("Y", paste0("X", 1:p))
ols <- lm(Y ~ ., df)
summary(ols)##
## Call:
## lm(formula = Y ~ ., data = df)
##
## Residuals:
## Min 1Q Median 3Q Max
## -3.3024 -1.6785 -0.5325 1.6759 4.2063
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -0.80068 0.21045 -3.805 0.000253 ***
## X1 -0.06854 0.21737 -0.315 0.753204
## X2 -0.07340 0.22268 -0.330 0.742433
## X3 -0.01231 0.22200 -0.055 0.955883
## X4 0.15328 0.20187 0.759 0.449566
## X5 -0.09480 0.22102 -0.429 0.668978
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 2.102 on 94 degrees of freedom
## Multiple R-squared: 0.01157, Adjusted R-squared: -0.041
## F-statistic: 0.2201 on 5 and 94 DF, p-value: 0.9531class(ols)## [1] "lm"predict(ols)## 1 2 3 4 5 6
## -0.8466142 -0.5500023 -0.8992452 -0.4872413 -0.7532348 -0.8425296
## 7 8 9 10 11 12
## -0.6692584 -0.8162210 -0.7691131 -0.9428197 -1.2205467 -0.6306511
## 13 14 15 16 17 18
## -1.0436556 -0.7739806 -0.6392084 -0.7110288 -1.0616260 -0.3217362
## 19 20 21 22 23 24
## -0.9223742 -0.6392848 -0.5225642 -0.7032897 -0.9370182 -1.0634000
## 25 26 27 28 29 30
## -0.9392657 -0.5489185 -0.5398687 -0.8362497 -0.5442889 -0.8389391
## 31 32 33 34 35 36
## -0.8999913 -0.6289889 -1.0035078 -0.7945077 -0.8974168 -0.6284758
## 37 38 39 40 41 42
## -1.1203263 -0.9797961 -1.2330808 -0.7039213 -0.9858462 -0.9522025
## 43 44 45 46 47 48
## -0.5711437 -0.9880247 -0.8444748 -0.7115474 -0.8318194 -1.0429827
## 49 50 51 52 53 54
## -0.9986723 -0.8391391 -0.7250816 -0.7315999 -0.9641818 -0.5468403
## 55 56 57 58 59 60
## -0.7657554 -1.1763156 -0.8306629 -1.0608708 -0.5520130 -0.5404172
## 61 62 63 64 65 66
## -1.3130770 -0.7961347 -0.8172254 -0.9659325 -0.4266729 -1.0805610
## 67 68 69 70 71 72
## -0.5982009 -0.7192003 -0.5474363 -0.8257202 -0.9346896 -0.8425413
## 73 74 75 76 77 78
## -0.6096661 -0.7735372 -0.8784366 -0.8872411 -0.9398991 -0.7309591
## 79 80 81 82 83 84
## -0.4472685 -0.4080720 -0.9593109 -0.3709285 -1.3096683 -0.7227044
## 85 86 87 88 89 90
## -0.8780641 -0.7603019 -0.3119936 -0.7293890 -0.9063437 -0.8402942
## 91 92 93 94 95 96
## -0.8011085 -0.9737516 -0.8073685 -0.9172409 -1.3326231 -0.9122026
## 97 98 99 100
## -0.8699353 -0.1898385 -0.7182788 -0.6951232#if you pass in a lm or glm, predict will use predict.lm or predict.glm anyways. It is smart.
#There is an argument in predict that uses "new data". You need to pass in what the new data is. It should be tempting for us to just pass in X1.
#This shouldn't work! But why?
#predict(ols, newdata = as.data.frame(X1))
#convert to df
#now there is an error that we don't know what X2 is. The data frame you are passing it needs to have the same names that you are training on.
names(df)## [1] "Y" "X1" "X2" "X3" "X4" "X5"df1 <- as.data.frame(X1)
names(df1) <- names(df)[-1]
test_preds <- predict(
ols,
newdata = df1)
#The data you are passing, you need the data to look identical to the data you trained the model with. The names of the data frames must agree.
#classic workflow
plot(test_preds , Y2)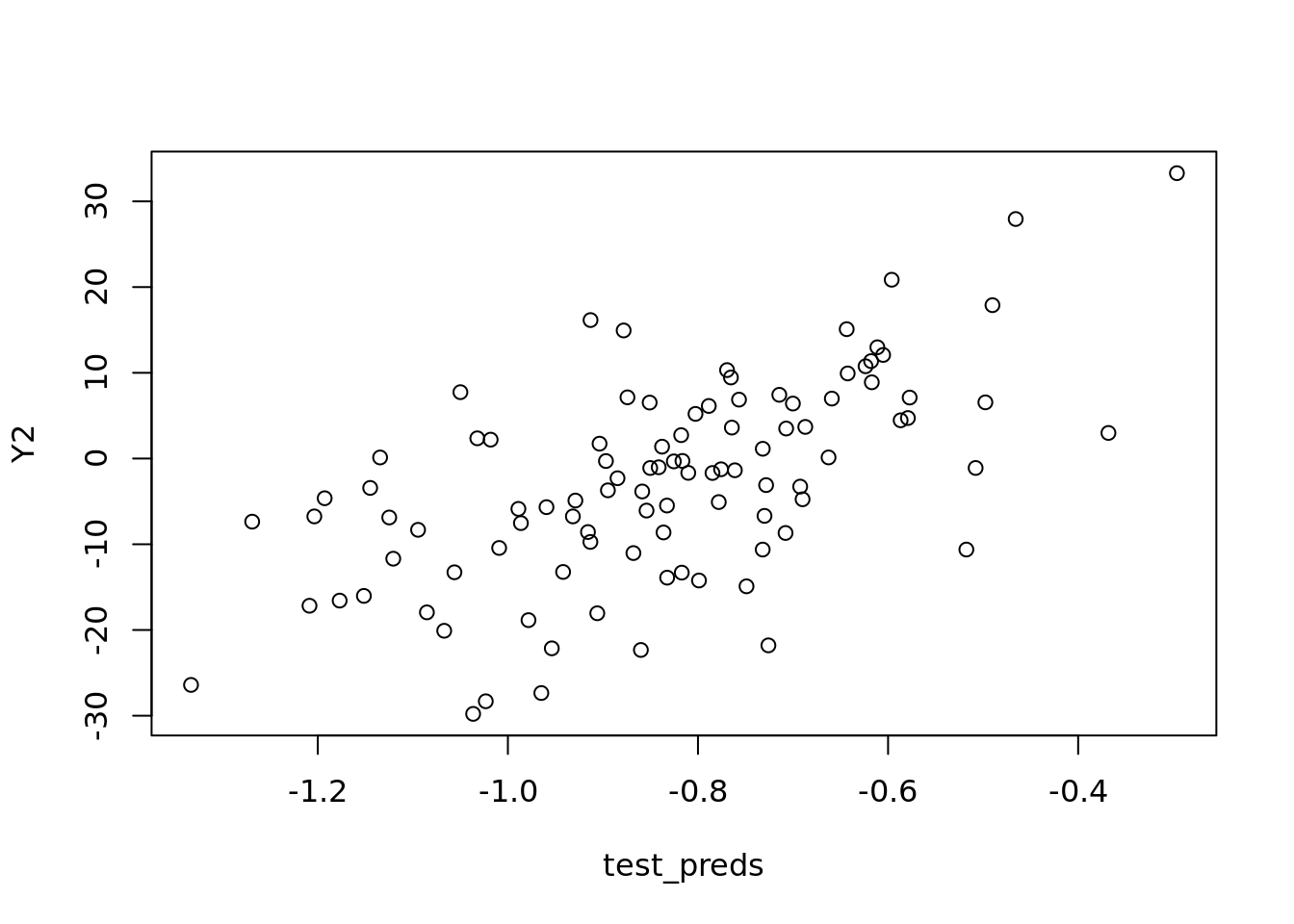
test_errors <- Y2 - test_preds
test_rmse <- sqrt(mean(test_errors ^ 2))
test_rmse## [1] 11.75753sd(noise)## [1] 0.9604043sd(noise1)## [1] 1.065565#You cannot reduce beyond this. R will automatically throw out extremely high colinearity instances. In the real world this would be rare. This is unique to R.
names(ols)## [1] "coefficients" "residuals" "effects" "rank"
## [5] "fitted.values" "assign" "qr" "df.residual"
## [9] "xlevels" "call" "terms" "model"#probably the most important
ols$coefficients## (Intercept) X1 X2 X3 X4 X5
## -0.80067547 -0.06854461 -0.07339731 -0.01231419 0.15328160 -0.09479590plot(ols$coefficients, c(0,params))
abline(a = 0, b=1)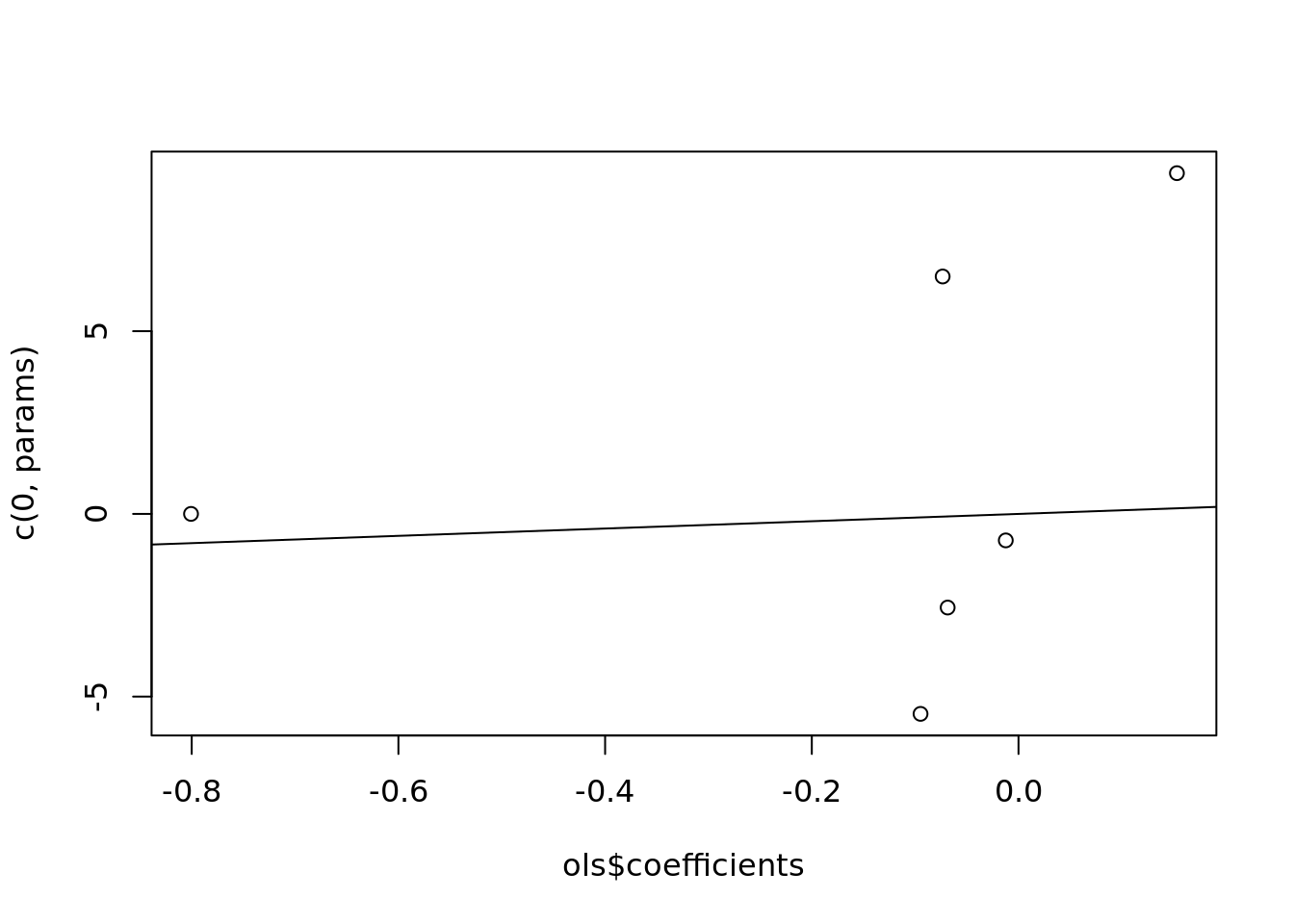
train_features <- cbind(1,as.matrix(df[,-1])) #take out y column
#fitted_vals <- train_features %*%
fitted_vals <- train_features %*% ols$coefficients
sum(abs(fitted_vals - ols$fitted.values))## [1] 7.954748e-14res <- df$Y - ols$fitted.values
sum(abs(res - ols$residuals))## [1] 5.689893e-16plot(ols$residuals)
abline(h = 0)
#you can also put plot onto the regression function itself
plot(ols)
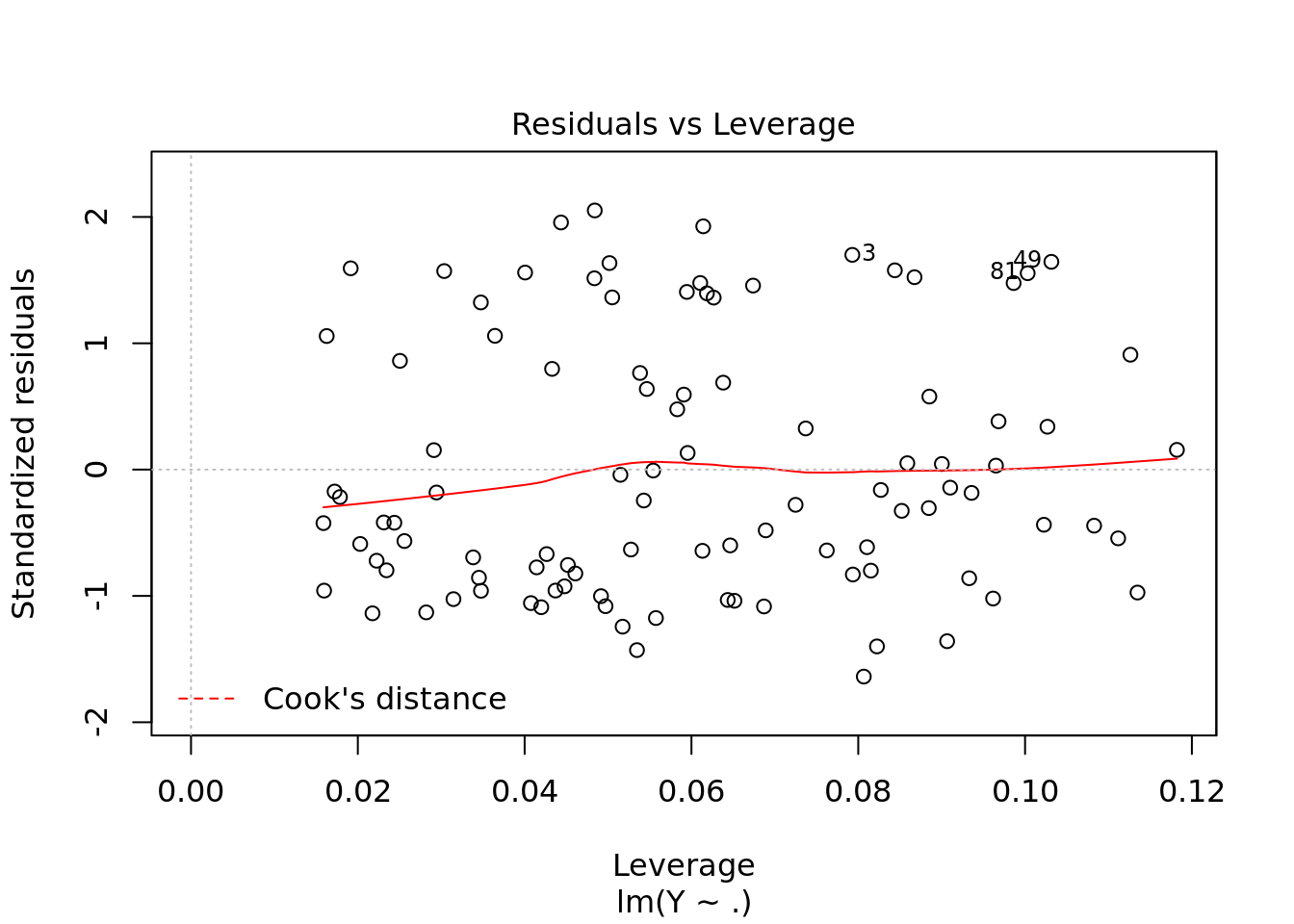
#residuals vs fitted values. This is what we saw earlier but much fancier
#QQ Plot
#scale location not that important
#leverage to look for outliers3.1.0.1 Traps
df_missing <- df
df_missing[20, "Y"] <- NA #purposeffully lose the value
ols <- lm(Y ~., df_missing)
length(ols$residuals)## [1] 99#lm drops missing value before matrix multiplication. So the residuals will change. 3.1.1 Interactions + subtracting variables
3.1.1.1 Another trap
ols <- lm(Y ~ X1 + X2 + X2*X3, df)
ols <- lm(Y ~ X1 + X2 + X2:X3, df)
summary(ols)##
## Call:
## lm(formula = Y ~ X1 + X2 + X2:X3, data = df)
##
## Residuals:
## Min 1Q Median 3Q Max
## -3.1755 -1.7025 -0.5164 1.6277 4.3279
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -0.79146 0.21051 -3.760 0.000292 ***
## X1 -0.08294 0.21541 -0.385 0.701074
## X2 -0.05373 0.21758 -0.247 0.805479
## X2:X3 0.06991 0.25185 0.278 0.781937
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 2.089 on 96 degrees of freedom
## Multiple R-squared: 0.003456, Adjusted R-squared: -0.02769
## F-statistic: 0.111 on 3 and 96 DF, p-value: 0.9535test_preds <- predict(ols, df1)
head(df1,2)## X1 X2 X3 X4 X5
## 1 -1.07142719 -1.1871989 -0.8844386 0.7901656 2.3611781
## 2 0.06528965 -0.9471535 -0.1001621 0.4594735 0.6965748#when you start manipulating the data inbetween then you get the problems
#If you do feature engineering for test, then ADD SOMETHINGols <- lm(Y ~ . - X4, df)
summary(ols)##
## Call:
## lm(formula = Y ~ . - X4, data = df)
##
## Residuals:
## Min 1Q Median 3Q Max
## -3.1062 -1.6155 -0.6362 1.6552 4.3852
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -0.7988528 0.2099621 -3.805 0.000251 ***
## X1 -0.0801909 0.2163431 -0.371 0.711712
## X2 -0.0460911 0.2192705 -0.210 0.833960
## X3 0.0001994 0.2208972 0.001 0.999282
## X5 -0.1136023 0.2191393 -0.518 0.605383
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 2.097 on 95 degrees of freedom
## Multiple R-squared: 0.005509, Adjusted R-squared: -0.03636
## F-statistic: 0.1316 on 4 and 95 DF, p-value: 0.9705#get rid of intercept
ols <- lm(Y ~ . -1, df)
summary(ols)##
## Call:
## lm(formula = Y ~ . - 1, data = df)
##
## Residuals:
## Min 1Q Median 3Q Max
## -4.0580 -2.4583 -1.3273 0.8825 3.4138
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## X1 -0.103445 0.232067 -0.446 0.657
## X2 -0.061040 0.237929 -0.257 0.798
## X3 0.001876 0.237194 0.008 0.994
## X4 0.144521 0.215698 0.670 0.504
## X5 -0.090330 0.236174 -0.382 0.703
##
## Residual standard error: 2.246 on 95 degrees of freedom
## Multiple R-squared: 0.01049, Adjusted R-squared: -0.04159
## F-statistic: 0.2013 on 5 and 95 DF, p-value: 0.9612INSERT STUFF ABOUT INTERACTION TERMS: COLON THING
3.2 Last trap, ording of the data
x <- runif(n, -2 ,2)
y <- x^2 * 3
ols <- lm(y~x)
summary(ols)##
## Call:
## lm(formula = y ~ x)
##
## Residuals:
## Min 1Q Median 3Q Max
## -3.426 -2.999 -1.280 2.085 7.910
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 3.4210 0.3440 9.944 <2e-16 ***
## x -0.2748 0.3216 -0.855 0.395
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 3.437 on 98 degrees of freedom
## Multiple R-squared: 0.007397, Adjusted R-squared: -0.002731
## F-statistic: 0.7304 on 1 and 98 DF, p-value: 0.3949predict(ols, data.frame(x = runif(n,-2,2)))## 1 2 3 4 5 6 7 8
## 3.840287 3.895530 3.082596 3.967011 3.183809 3.882475 3.420739 3.559022
## 9 10 11 12 13 14 15 16
## 3.511337 3.744857 3.566703 3.870124 3.337779 3.805869 3.401721 3.747448
## 17 18 19 20 21 22 23 24
## 3.201034 3.965527 3.631151 3.007863 3.415257 2.871489 3.526979 3.212339
## 25 26 27 28 29 30 31 32
## 3.806844 3.512686 3.909634 3.461472 3.467289 2.961054 2.937773 3.132825
## 33 34 35 36 37 38 39 40
## 3.114901 3.300550 3.950654 3.190817 3.861283 2.929397 3.928009 3.955799
## 41 42 43 44 45 46 47 48
## 3.614185 3.311400 3.077159 3.409506 3.264064 3.006801 3.401457 2.944016
## 49 50 51 52 53 54 55 56
## 3.411810 3.483600 3.728660 2.958274 3.070491 2.998553 2.927704 3.145053
## 57 58 59 60 61 62 63 64
## 2.930598 3.750936 3.860646 3.646931 3.817446 3.630312 2.994190 3.312688
## 65 66 67 68 69 70 71 72
## 3.727644 3.878689 3.813655 3.788756 3.420362 2.928994 3.479459 3.545394
## 73 74 75 76 77 78 79 80
## 3.581095 3.591661 2.936144 3.151186 3.362050 3.261028 3.818321 3.676123
## 81 82 83 84 85 86 87 88
## 3.226600 3.946157 3.969481 3.076348 3.911955 3.784175 3.953343 3.682453
## 89 90 91 92 93 94 95 96
## 3.537163 3.366881 3.863851 3.719945 3.553456 3.158104 2.877040 3.200288
## 97 98 99 100
## 3.785358 3.805815 2.927946 3.623890predict(ols, data.frame(x = runif(n, -2,2)))## 1 2 3 4 5 6 7 8
## 3.109591 3.921111 3.429573 3.718912 3.908007 3.510022 2.968095 3.316154
## 9 10 11 12 13 14 15 16
## 2.921517 3.266529 3.375247 3.151179 3.854968 3.297138 3.949759 3.607904
## 17 18 19 20 21 22 23 24
## 3.066055 3.963296 3.249269 3.440945 3.463565 3.224241 3.350758 3.934221
## 25 26 27 28 29 30 31 32
## 3.263613 3.209258 3.332712 3.198461 3.607299 3.758238 3.749192 3.290177
## 33 34 35 36 37 38 39 40
## 3.439731 3.872702 3.700448 3.909168 3.002585 3.302670 3.752721 3.793311
## 41 42 43 44 45 46 47 48
## 3.202104 3.009737 3.682404 3.926455 3.080774 3.229446 3.170134 3.210652
## 49 50 51 52 53 54 55 56
## 2.909685 3.371818 3.881306 3.863863 3.698930 3.827869 3.281986 3.230568
## 57 58 59 60 61 62 63 64
## 3.712393 3.092416 3.411363 3.373810 2.874708 3.641461 2.951438 2.917634
## 65 66 67 68 69 70 71 72
## 3.910263 3.837779 3.624870 2.902349 2.901413 3.164566 3.022147 3.452001
## 73 74 75 76 77 78 79 80
## 3.775202 3.599949 3.550948 3.308599 3.040813 3.475173 3.229017 3.037894
## 81 82 83 84 85 86 87 88
## 2.913443 3.222908 3.834751 3.233537 3.738819 3.113187 3.780592 3.963543
## 89 90 91 92 93 94 95 96
## 3.540378 3.241221 3.615064 3.019241 3.320209 3.500647 3.661962 3.798940
## 97 98 99 100
## 3.768286 3.560545 2.981589 3.402344plot(x,y)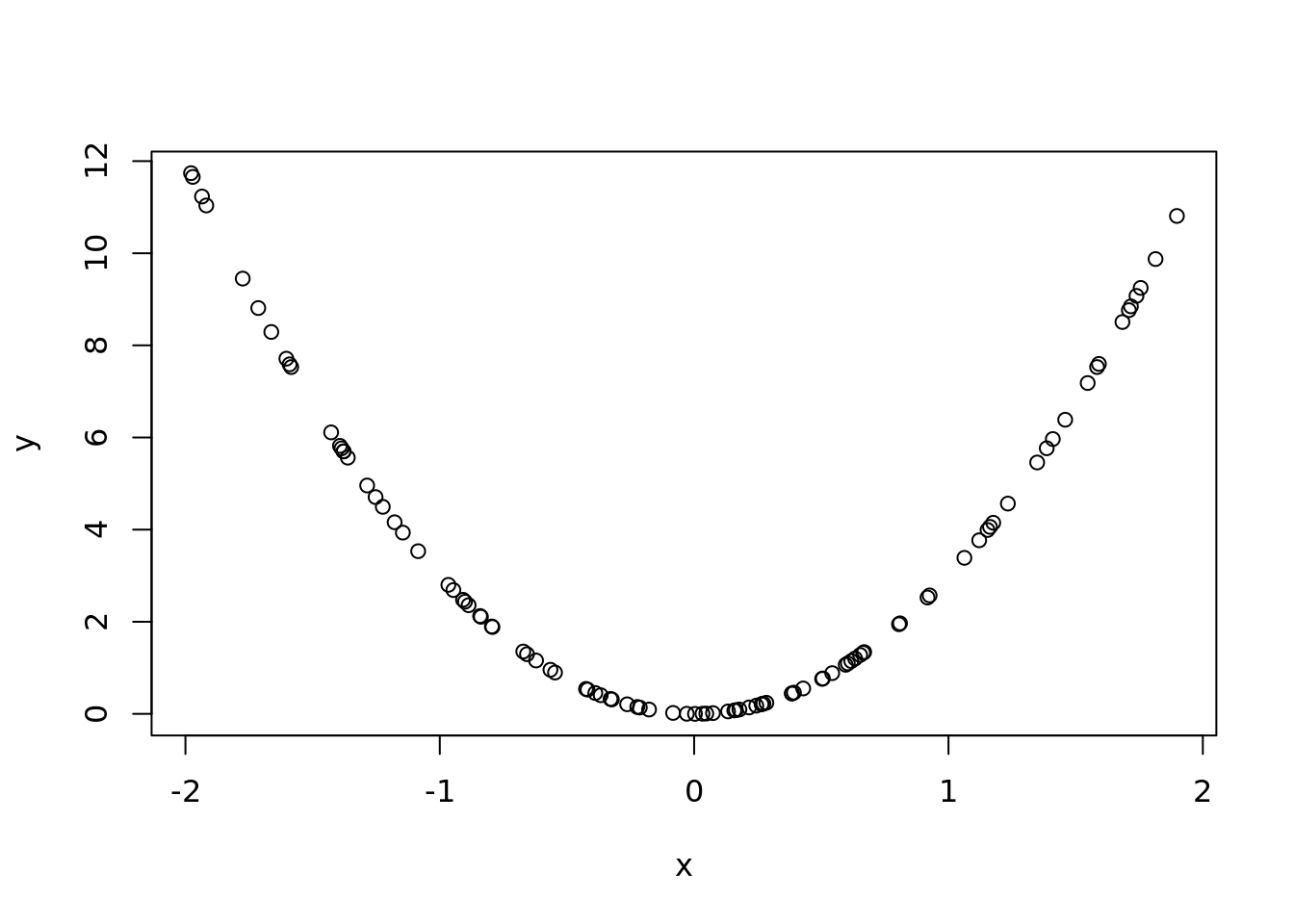
plot(ols$residuals)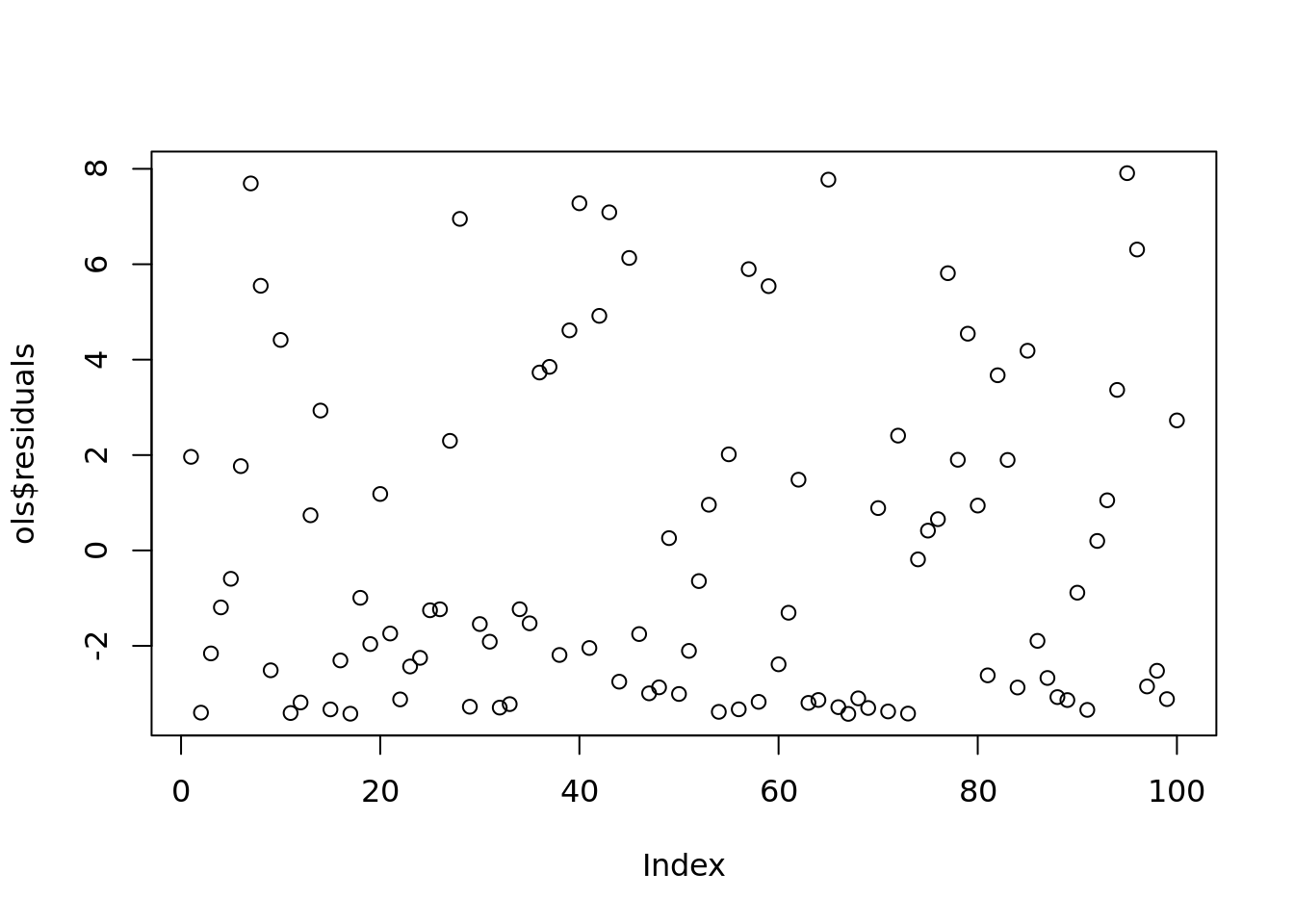
#we should expect the residuals to be quadratic as well
# we need to order the data correctly
plot(ols$fitted.values,
ols$residuals)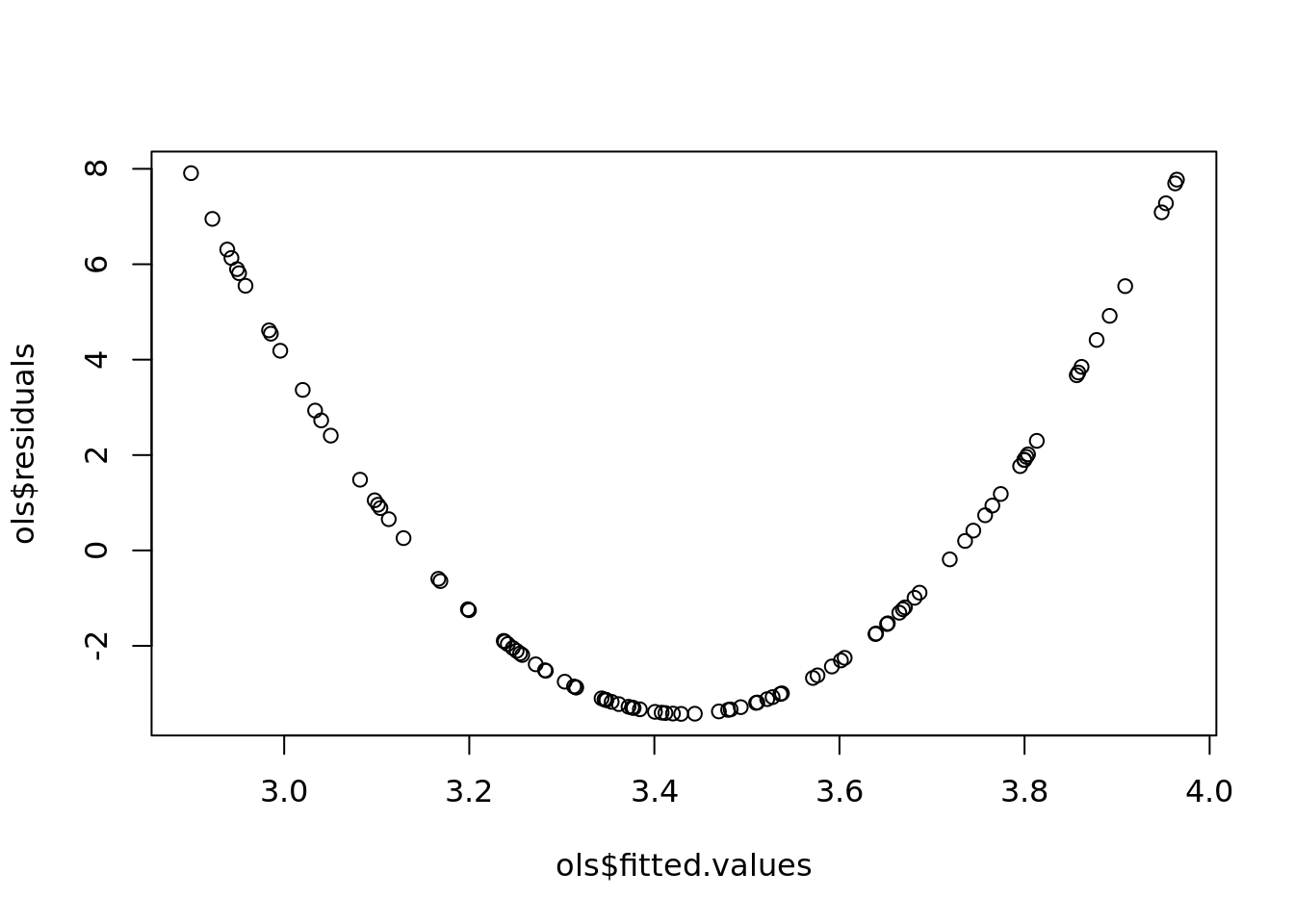
#remember the reisdualds are ordered the same as the data. If the data was random, then the residuals will be random.
plot(ols)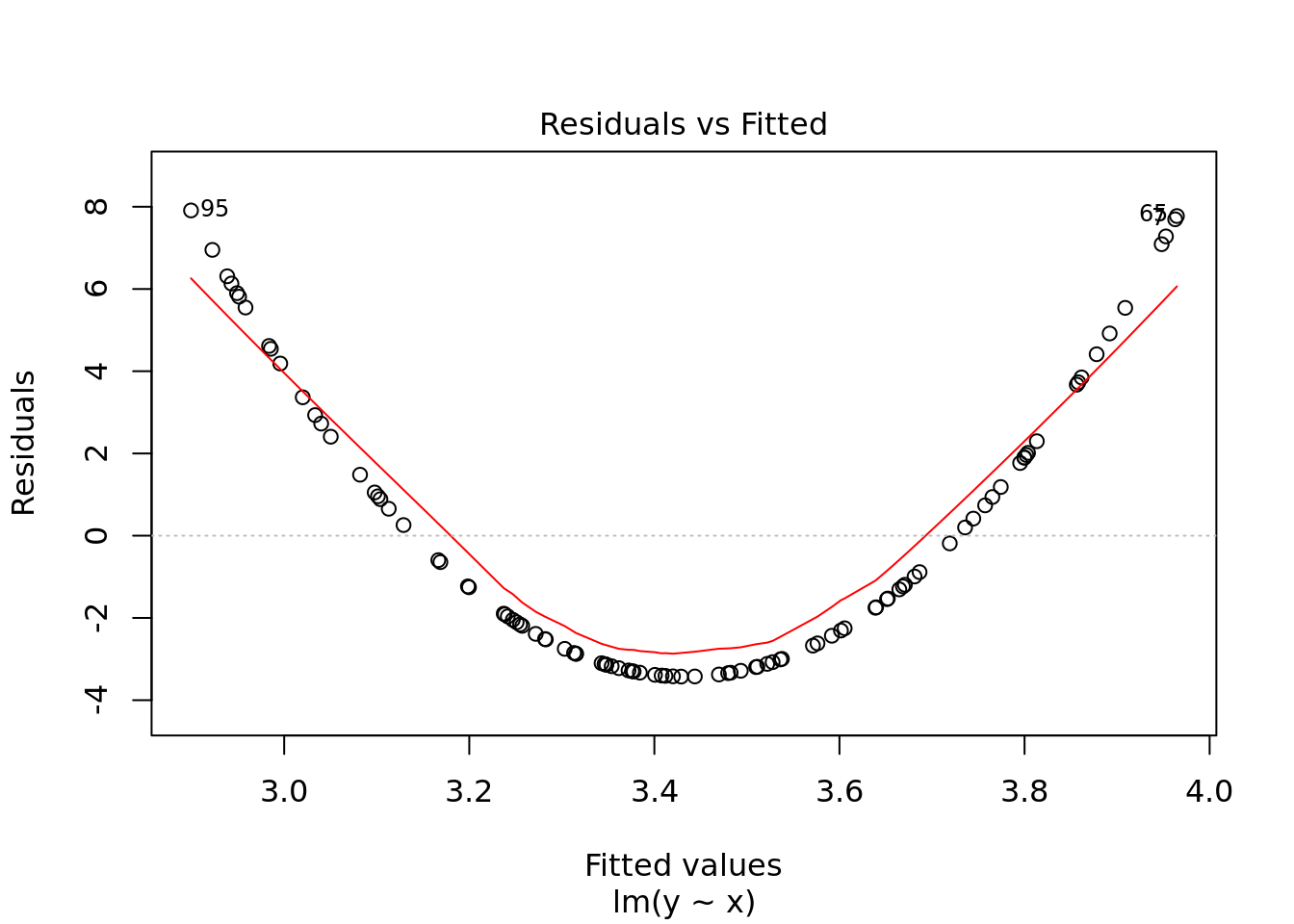
#naming comment
#If we decided to
dim(X)## [1] 100 5length(Y)## [1] 100ols <- lm(Y ~ X[,1:2])
summary(ols)##
## Call:
## lm(formula = Y ~ X[, 1:2])
##
## Residuals:
## Min 1Q Median 3Q Max
## -3.2287 -1.7356 -0.5143 1.5971 4.2827
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -0.79833 0.20806 -3.837 0.000222 ***
## X[, 1:2]1 -0.08604 0.21409 -0.402 0.688664
## X[, 1:2]2 -0.06260 0.21419 -0.292 0.770699
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 2.079 on 97 degrees of freedom
## Multiple R-squared: 0.002656, Adjusted R-squared: -0.01791
## F-statistic: 0.1292 on 2 and 97 DF, p-value: 0.879#the naming is a mess!
wrong_stuff <- predict(ols, data.frame("X[, 1:2]" = 1:3,
"X[, 1:2]2" = 1:3))## Warning: 'newdata' had 3 rows but variables found have 100 rowsmysterious_vals <- predict(ols)
sum(abs(mysterious_vals - ols$fitted.values))## [1] 5.928591e-143.2.1 Missing
If there is no overlap in the data. Then there is no overlapping data. You can’t run regression in that case.
you should probably have a reason to say you need a certain amount of overlap. The best way to get there is to find the needed level of confidence and then back in the answer.
3.2.2 GLM
inv_logit <- function(x) {
return(exp(x) / (1 + exp(x)))
}
y <- rbinom(n, 1, prob = inv_logit(X %*% params))
plot(X[, 1], y)
plot(X[, 2], y)
df <- as.data.frame(cbind(y, X))
names(df) <- c("Y", paste0("X", 1:5))
log_reg <- glm(Y ~ ., df,
family = binomial(logit))## Warning: glm.fit: fitted probabilities numerically 0 or 1 occurredsummary(log_reg)##
## Call:
## glm(formula = Y ~ ., family = binomial(logit), data = df)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -1.55700 -0.00719 0.00000 0.03442 2.65678
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) -0.7443 0.7479 -0.995 0.31959
## X1 -2.8064 1.3453 -2.086 0.03697 *
## X2 7.6632 2.9431 2.604 0.00922 **
## X3 -1.0879 0.7398 -1.471 0.14142
## X4 8.2142 2.8049 2.928 0.00341 **
## X5 -3.7470 1.6072 -2.331 0.01974 *
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for binomial family taken to be 1)
##
## Null deviance: 138.589 on 99 degrees of freedom
## Residual deviance: 15.224 on 94 degrees of freedom
## AIC: 27.224
##
## Number of Fisher Scoring iterations: 10predict(log_reg)## 1 2 3 4 5 6
## -3.6999292 9.5341582 -7.3779002 13.4527094 -10.5669276 -1.2529507
## 7 8 9 10 11 12
## 17.6467846 15.9095184 7.1672730 -14.1199174 -25.0201866 -0.5651663
## 13 14 15 16 17 18
## 2.6977897 -17.6902202 -16.4415932 12.9883464 -11.6574498 3.9836565
## 19 20 21 22 23 24
## -17.8344357 -4.9540985 0.9221493 -3.4323721 12.5637357 -24.9717316
## 25 26 27 28 29 30
## -20.9472646 11.5810627 -14.3785402 6.5527647 36.6323550 -0.7782374
## 31 32 33 34 35 36
## -17.5822125 12.1382850 -34.1483668 -13.3531265 -9.0331685 5.8818887
## 37 38 39 40 41 42
## -2.0841276 6.4988135 -12.0355978 4.7239670 3.4600884 -8.6990285
## 43 44 45 46 47 48
## 14.3504032 5.1436945 7.3833474 -12.1453353 14.3935154 -16.7825635
## 49 50 51 52 53 54
## -10.5554323 -16.5965524 1.7658996 -2.5617125 -3.4994745 3.5194480
## 55 56 57 58 59 60
## 1.1950382 -14.8082792 -9.8658048 -27.7611566 3.6309294 10.2953611
## 61 62 63 64 65 66
## -11.8484967 6.8784387 4.8006735 -6.7060764 10.1062385 -7.3193777
## 67 68 69 70 71 72
## 10.4309024 -20.9561651 -7.1760829 19.0406735 -13.7600290 0.8589286
## 73 74 75 76 77 78
## 9.1013287 -4.0438335 4.0662245 3.7384007 16.9113042 9.0109326
## 79 80 81 82 83 84
## 6.8157417 38.8337582 7.4470155 18.5934908 -10.5890653 4.8936962
## 85 86 87 88 89 90
## -5.3470952 -10.8186533 20.7228728 1.2541601 6.5458611 -4.8358950
## 91 92 93 94 95 96
## -19.0178771 -2.8661972 -5.7269349 -1.6268291 -19.1615157 -9.0543194
## 97 98 99 100
## -5.7117029 19.6122543 15.8195372 7.1440199myst_vals <- predict(log_reg, type = "response")
X_test <- matrix(rnorm(n * p), nrow = n)
X_test_df <- as.data.frame(X_test)
names(X_test_df) <- names(df)[-1]
test_preds <-
predict(log_reg, type = "response", newdata = X_test_df)
head(test_preds)## 1 2 3 4 5
## 4.876127e-03 4.349450e-09 1.000000e+00 9.505656e-01 9.492657e-01
## 6
## 9.437559e-01params## [1] -2.5628620 6.4970846 -0.7251178 9.3246968 -5.4726339